再读istio官方文档的笔记
动态请求路由:按权重和匹配规则(版本粒度)
故障恢复:超时、重试、熔断器(版本的粒度?)
故障注入:测试服务之间是否有影响。(服务粒度?)
pilot负责部署在网格应用之间的envoy示例的生命周期管理
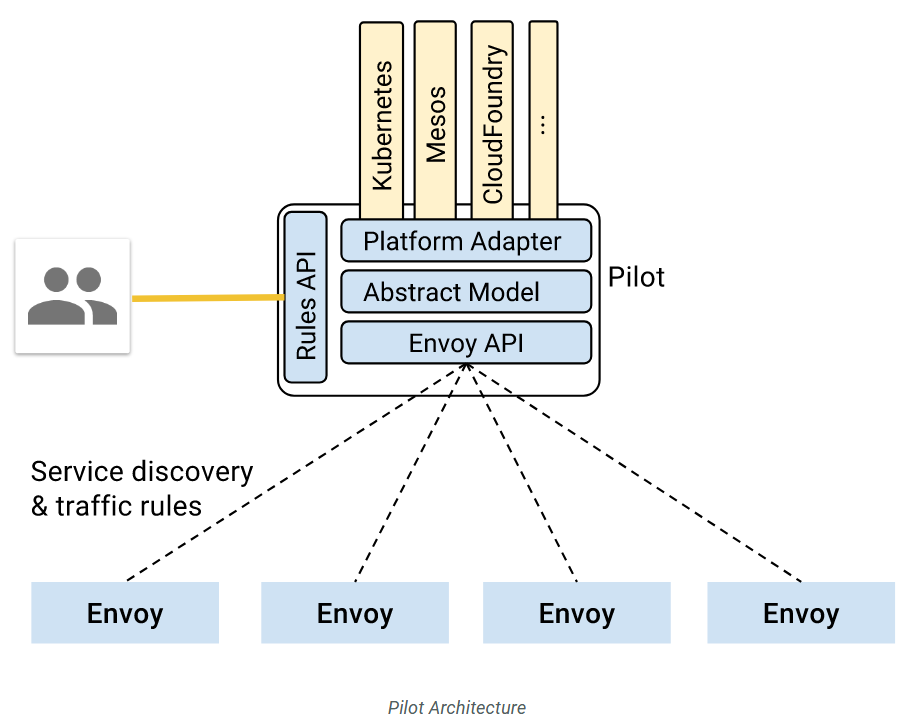
dr和vs就是pilot的rules api。
pilot如何发现这些配置更改了?
然后通过envoy API分发规则到各个服务组件的envoy里面去?
动态请求路由、流量管理的其他用法:
路由规则允许Envoy根据诸如header,与源/目的地相关联的标签和/或分配给每个版本的权重的标准来选择版本。
ingress 内部金丝雀,abtest等访问;
egress 熔断、错误注入这些功能??再理解
发现和负载均衡:
Envoy遵循熔断器风格模式,根据健康检查API调用的失败率将实例分类为不健康或健康。换句话说,当给定实例的健康检查失败次数超过预定阈值时,它将从负载均衡池中弹出。类似地,当通过的健康检查数超过预定阈值时,该实例将被添加回负载均衡池。
服务可以通过使用HTTP 503响应健康检查来主动减轻负担。在这种情况下,服务实例将立即从调用者的负载均衡池中删除。
处理故障:
Envoy提供了一套开箱即用, 选择加入的故障恢复功能,可以在应用程序中受益。功能包括:
1. 超时
2. 带超时预算有限重试以及重试之间的可变抖动
3. 并发连接数和上游服务请求数限制
4. 对负载均衡池的每个成员进行主动(定期)运行健康检查
5. 细粒度熔断器(被动健康检查)- 适用于负载均衡池中的每个实例
Istio启用协议特定的故障注入到网络中,而不是杀死pod,延迟或在TCP层破坏数据包。我们的理由是,无论网络级别的故障如何,应用层观察到的故障都是一样的,并且可以在应用层注入更有意义的故障(例如,HTTP错误代码),以锻炼应用的弹性。
可以注入两种类型的故障:延迟和中止。延迟是计时故障,模拟增加的网络延迟或过载的上游服务。中止是模拟上游服务的崩溃故障